



Self-Healing at Scale
Cloud infrastructure is inherently unreliable. To achieve resiliency at scale, self-healing mechanisms must come into play.

Standalone Kubernetes can drive your cloud costs up the proverbial wall and ruin your self esteem. (You are not alone. Overprovisioning as high as 30% is not uncommon these days.) Perhaps it’s time for architecting self-healing applications that improve resiliency without breaking the bank.
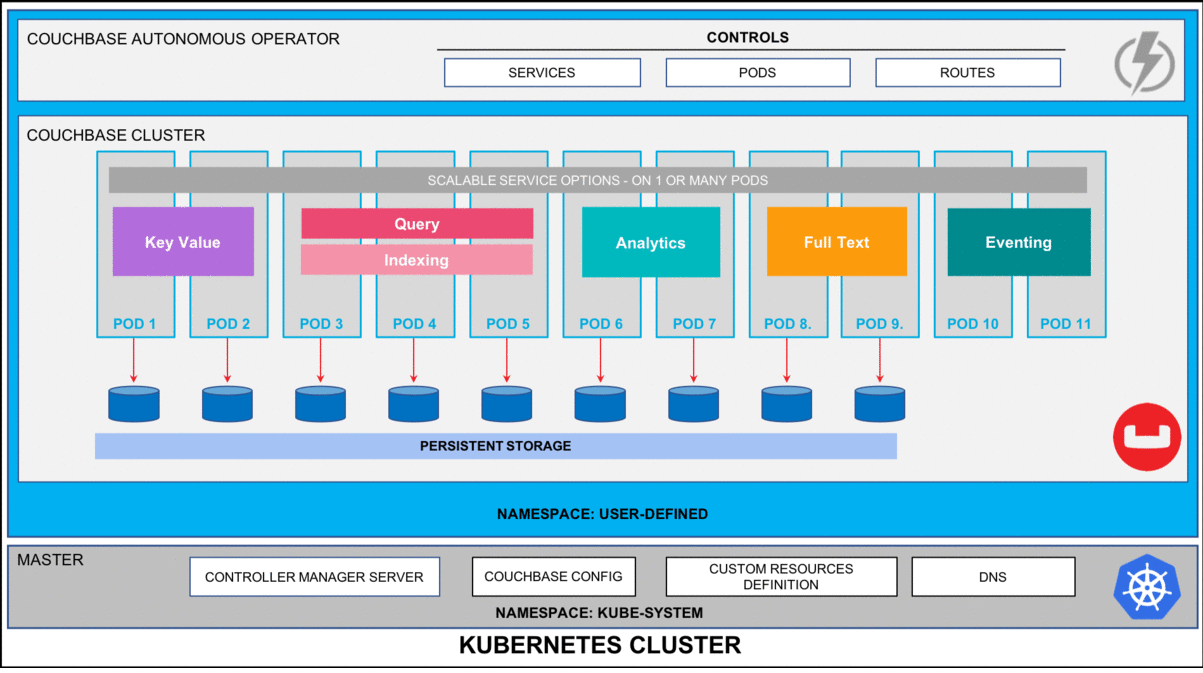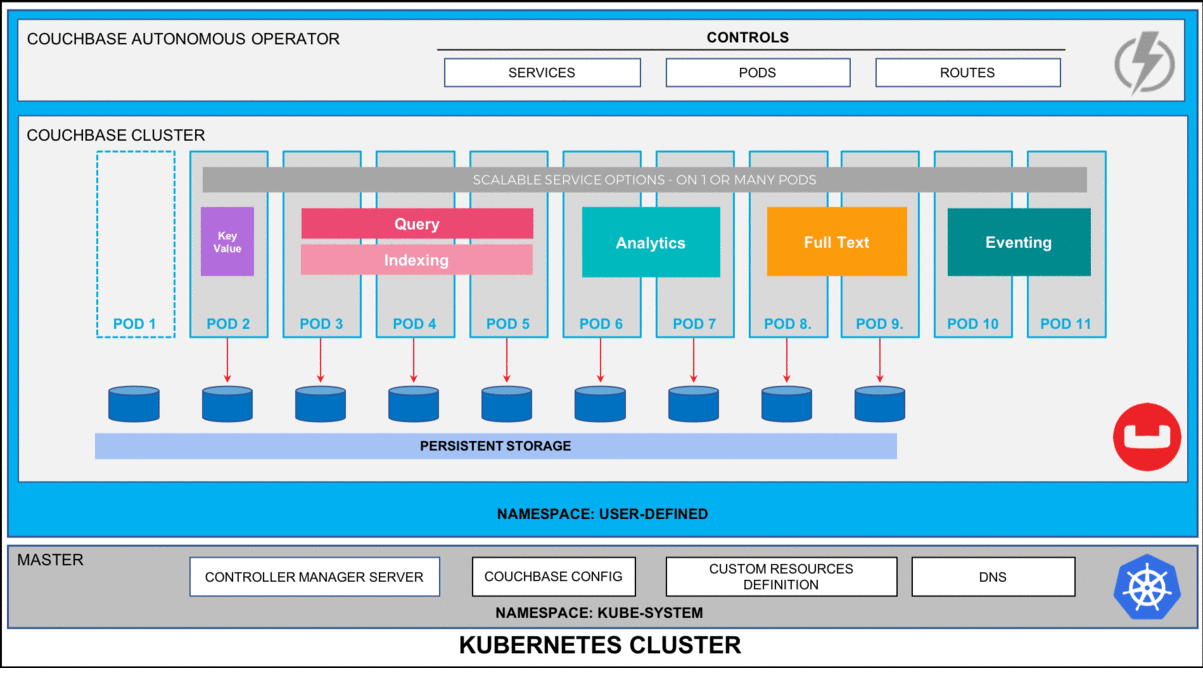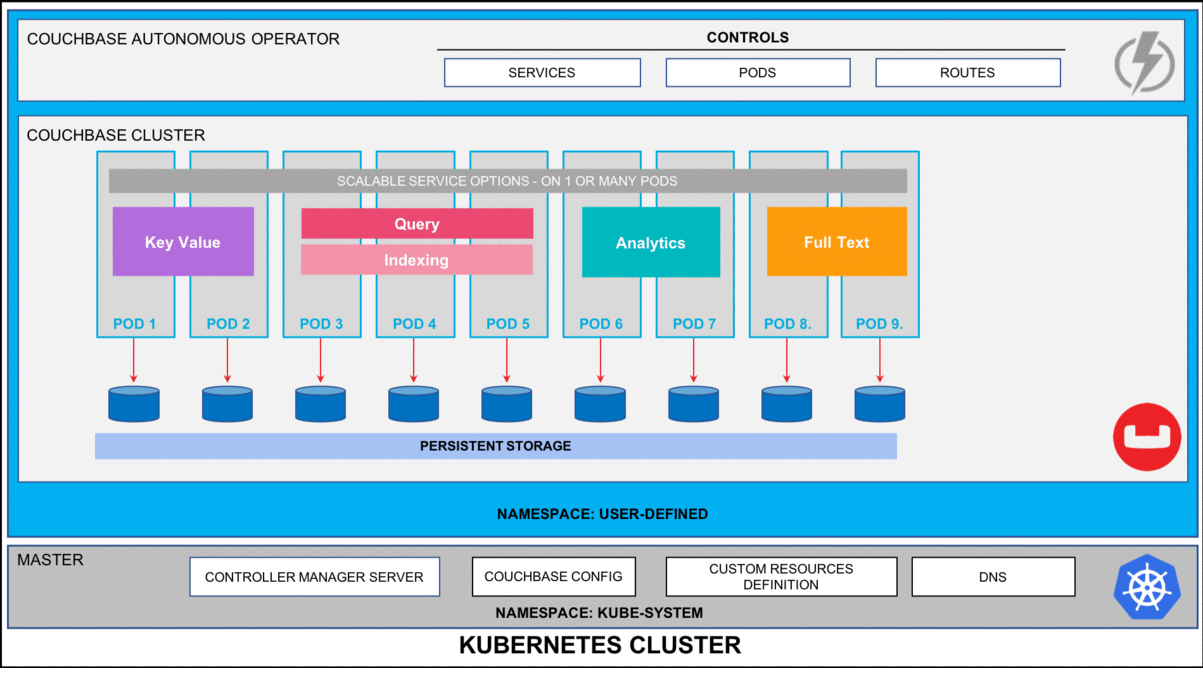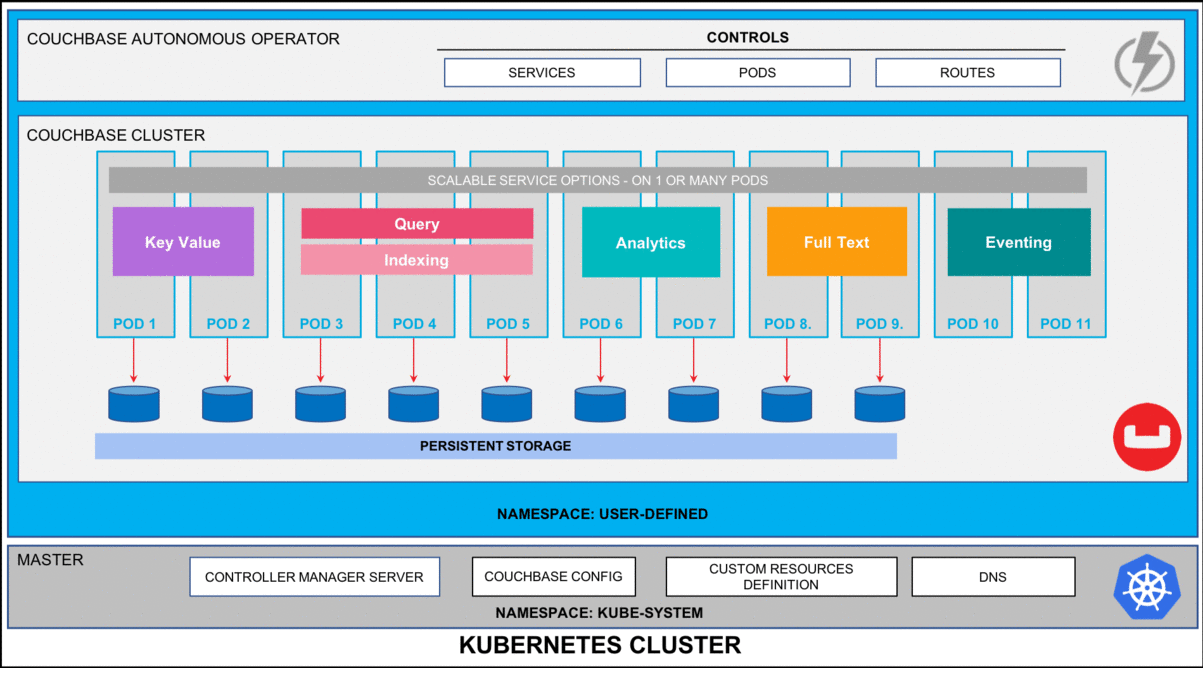
According to the Consortium for Information & Software Quality (CISQ), software failures in the U.S. alone cost about $1.56 trillion in 2022—or roughly 144% of Germany’s annual tax revenue. Such costs arise because our physical reality is increasingly controlled by software.
When code fails, parts of the economy come to a standstill. A software malfunction can halt production lines or impact quality of goods and services, causing disruptions that ripple through the supply chain.
One Heck of a Glitch
Operational challenges with software can arise from poor code quality, malicious code injection, performance bottlenecks, hardware failures, external service outages and the like. Architecting self-healing software goes beyond scripted rebooting of zombified server instances or failing over to a replica. Self-healing demands dynamic resilience.
In August 2023, a known bug in the flight control software of the UK’s air traffic authority (NATS) caused a system-wide outage. The glitch was triggered by a flight plan with two identically named waypoints outside UK airspace. The software failed to validate the input, crashing both the primary system and its replica.
Despite being aware of the issue, NATS underestimated its impact. Widespread flight cancellations ensued. Out of a sudden, more than a quarter of a million passengers were stranded.
For all we know, a monolithic legacy application was at fault here. Yet one mistake, in one location, rippled through the entire airspace, worldwide.
Two years in, disruptive software bugs, along with network and power outages, are still a common occurrence. It does not have to be this way. We don’t have to put up with nonsense. Reckless ignorance does not have to be tolerated. Not in monolithic legacies of yesteryear, nor in distributed systems that will be here tomorrow.
Self-Healing Distributed Architectures
Distributed software can monitor its key metrics—such as latency, throughput, and error rates—allowing it to detect and address issues autonomously. Tools like Prometheus, Grafana, and Elastic Stack enable monitoring and alert management, while solutions like PagerDuty automate incident responses.

Here’s an example of Prometheus monitoring:
# Alerting Rule in Prometheus
alert: HighErrorRate
expr: rate(http_requests_total{status="500"}[5m]) > 1
for: 10m
labels:
severity: critical
annotations:
summary: High request error rate detected on {{ $labels.instance }}
description: "{{ $labels.instance }} is experiencing 5xx errors above 1 per second."
The integration of Prometheus with Kubernetes’ alert manager can trigger actions like service restarts or autoscaling, contributing to the system's resilience.
Kubernetes and the Practicalities of Self-Healing
Kubernetes offers several built-in features that can address your requirements for resiliency:
health checks and self-healing,
automatic rollbacks,
auto-scaling,
load balancing.
Its probes—liveness and readiness—check whether containers function correctly and whether they can handle traffic, respectively. When a container malfunctions, Kubernetes can remove it from service and attempt a restart.

In case of a CrashLoopBackOff—when a container repeatedly fails to launch—the backoff algorithm gradually extends restart intervals to prevent overload. Additionally, rolling updates ensure seamless transitions between software versions, minimizing downtime.

Yet, Kubernetes isn’t all it’s cracked up to be. Issues such as corrupted container images or cluster-wide node failures still require more sophisticated counter-measures. Cross-cloud orchestration remains a challenge, as K8s platforms such as Amazon EKS or Azure AKS don’t have much of an incentive to integrate smoothly with each other.

Extending Kubernetes
Self-healing capabilities of Kubernetes can be extended with tools such as Spring Boot Actuator. This tool provides detailed application monitoring through HTTP endpoints or JMX, which Kubernetes can use to assess the health of a service.

Here’s an example configuration using Spring Boot:
livenessProbe:
httpGet:
path: /actuator/health/liveness
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8080
initialDelaySeconds: 15
periodSeconds: 5
Such integration enables Kubernetes to dynamically scale applications using horizontal pod autoscalers (HPA), based on metrics provided by Actuator.
Self-Healing Using Artificial Intelligence, Are We There Yet?
Modern self-healing systems leverage AI, machine learning, and predictive analytics to anticipate and mitigate failures.

Approaches such as Bayesian networks and the likes can model dependencies between variables, predicting potential issues before they arise.
Similarly, Artificial Immune Systems (AIS), inspired by the human immune system, can monitor software for anomalies, learn from past incidents, and adjust accordingly.
AIS uses three types of “cells”:
Detectors: Identify bugs or vulnerabilities.
Memory Cells: Store information on past incidents.
Antibodies: Trigger corrective actions when needed.
By mimicking the adaptive and memory functions of the human immune system, AIS can enhance both the resilience and responsiveness of an application. (The human immune system is a lot more sophisticated, though, so let’s not loopback to conclusions outside of infotech. No information on this site may be understood as medical advice.)
Balancing Different Strategies
While self-healing systems excel at reacting to known problems, unexpected failures can still slip through. Moreover, such systems often require human intervention for complex recovery procedures.
Emerging AIOps platforms aim to bridge this gap by using historical data to predict and prevent issues proactively. They come with their own perils, but that’s something for another day.
The Bottom Line
Combining development frameworks such as Spring Boot or Quarkus with Kubernetes can offer a robust foundation for building self-healing applications that maximize uptime for continuous service availability in real-world production environments. The ground is shifting, though.